
))
HBO and The Ringer's Bill Simmons hosts the most downloaded sports podcast of all time, with a rotating crew of celebrities, athletes, and media staples, as well as mainstays like Cousin Sal, Joe House, and a slew of other friends and family members who always happen to be suspiciously available.
…
continue reading
Manage episode 516816992 series 3451473
Content provided by Latent.Space. All podcast content including episodes, graphics, and podcast descriptions are uploaded and provided directly by Latent.Space or their podcast platform partner. If you believe someone is using your copyrighted work without your permission, you can follow the process outlined here https://staging.podcastplayer.com/legal.
One of the most potentially gamechanging announcements of the past month was OpenAI and Stripe’s collaboration to add Instant Checkout to ChatGPT:
There have been many attempts at monetizing agents (x402) and working out agent to agent protocols, including over MCP, but the entry of two category leaders in AI and payments is obviously impactful and needs to be watched closely.
Emily Glassberg Sands, Stripe’s Head of Data & AI, joined us today to talk about Stripe’s new mission to build the economic infrastructure for AI, and how they both use AI internally and see it as an advantage for the next phase of economic growth.
Inside ACP: the low level spec for agent payment

ACP is Stripe’s protocol jointly developed with OpenAI, which powers ChatGPT Commerce; it lets agents discover and purchase from merchant catalogs across ecosystems. The core components:
Catalog schema. Products, inventory, pricing, brand constraints, etc.
Shared payment token (more below)
Risk signal. “Good bot/bad bot” scores ride with the token so merchants can decision intelligently.
The ACP is being coupled with Stripe’s Link product, which has 200m+ consumers, as the wallet for your credentials. (Fun fact: 58% of Lovable revenue comes from Link transactions)
SharedPaymentToken (SPT) design:
Scoped to specific business, time-limited, amount-capped, revocable. Buyers use existing saved payment methods without re-entry
Underlying credentials are never exposed to agent and it’s designed for compatibility with card network agentic tokens like Mastercard’s
When processed via Stripe, includes Radar risk signals (fraud likelihood, card testing indicators, stolen card signals, etc)
Building a foundation model for payments
Emily has talked about this elsewhere, but it needed to be covered.
ML for fraud detection was one of the “old” AI markets, but it was not super reliable. Stripe only had 59% accuracy on card testing transactions for example. Move from task‑specific models to a transformer-based domain foundation model that produces dense payments embeddings to power many downstream tasks:
Treat each charge as a token and behavior sequences as the context window.
Ingest tens of billions of transactions (50,000/min) with full feature breadth: IPs, BINs, amounts, methods, geography, device, merchant traits, and more.
Focus on “last‑K” relevant events across heterogeneous actors and surfaces (login, checkout attempts, retries, issuer responses).
It lifted large‑merchant card‑testing detection from 59% to 97% and also helps merchant with transaction clustering, checkout optimization to understand user flows, etc. Every single Stripe transaction goes through this model in <100ms.
AI has added new types of fraud too as the cost of inference is now meaningful. A free trial abuse with a virtual credit card in the past would be annoying, but the cost of serving that user was low. Fraudsters are now burning tens of thousands of dollars of AI tokens using virtual credit cards or through chargebacks, which makes this much more important to get right.
Token Billing vs Outcome pricing
Everyone is a big fan of the pareto frontier charting for model capabilities, but it’s extremely hard as a product builder to offer the user choice while having a static plan. At the same time, users don’t want to use dumber models just to fit your pricing and they’ll often want to pay more for more intelligence. Stripe built Token Billing which calculates billing based on the model:
effective_price_per_unit = base_margin + (model_tokens_used * provider_unit_cost) + overheadThe other approach that companies are taking is outcome based pricing, which we also covered in our Dharmesh Shah episode. Intercom charging $1 per solved customer support ticket is an example.
Stripe’s internal AI stack
Toolshed (MCP server). Central tool layer wired into Slack, Drive, Git, data catalog (Hubble), query engines, and more. Agents can both retrieve and act using tools.
Text‑to‑SQL assistants.
External: Sigma Assistant works well because revenue data is canonical.
Internal: “Hubert” (used by ~900 people/week) sits on Hubble for broad data; biggest failure mode is data discovery. Most of their work has been on deprecating low‑quality tables, creating human‑owned docs for canonical datasets, and persona context (“which org you’re in”) to give as system prompts to bias table selection.
Semantic events + real‑time canonicals. Re‑architecting payments and usage billing pipelines so the same near‑real‑time feed powers Dashboard, Sigma, and data exports (e.g., BigQuery) with one source of truth that LLMs can consume.
Engineer adoption. ~8.5k Stripes/day use LLM tools; 65–70% use AI coding assistants. “Impact” measured beyond LOC/PR counts and more empirically on developer perceived productivity.
LLM‑built integrations. A pan‑EU local payment method integration went from ~2 months → ~2 weeks, trending to days.
The AI economy Stripe sees in the data
We figured we’d get some #s to fuel the “AI startup bubble” discourse on X :)
Go‑to‑market velocity. Top 100 AI companies on Stripe hit $1M/$10M/$30M ARR 2–3× faster than a comparable SaaS cohort five years prior.
Global from day one. ~2× the country count by year end; median AI company operates in 55 countries in year one, >100 in year two.
Retention dynamics. Per‑company retention slightly lower than SaaS, but churn is often switching, not abandoning the problem; customers boomerang as products leapfrog.
Tiny teams, big revenue. Revenue per employee outpaces elite public benchmarks. Unit economics depend on inference costs trending down; plan for volatility rather than current spot prices.
7x growth rate. Companies on Stripe grew 7x faster than S&P 500 last year.
Full Video Pod
On YouTube now!
Timestamps
00:00:00 — Introduction and Emily’s Role at Stripe
00:09:55 — AI Business Models and Fraud Challenges
00:13:49 — Extending Radar for AI Economy
00:16:42 — Payment Innovation: Token Billing and Stablecoins
00:23:09 — Agentic Commerce Protocol Launch
00:29:40 — Good Bots vs Bad Bots in AI
00:40:31 — Designing the Agents Commerce Protocol
00:49:32 — Internal AI Adoption at Stripe
01:04:53 — Data Discovery and Text-to-SQL Challenges
01:21:00 — AI Economy Analysis: Bubble or Boom?
Show Notes
Transcript
Alessio [00:00:00]: Hey everyone, welcome to the Latent Space podcast. This is Alessio, founder of Kernel Labs, and I’m joined by Swyx, editor of Latent Space.
Introduction and Emily Sands’ Role at Stripe
Swyx [00:00:03]: Hello, hello. We’re back in the studio with Emily Sands from Stripe. Welcome.
Emily [00:00:13]: Thank you.
Emily’s role as head of data and AI at Stripe and company overview
Swyx [00:00:14]: So Emily, you’re head of data and AI at Stripe. That’s a big title. What does that actually mean in practice?
Emily [00:00:21]: So Stripe is building financial infrastructure for the internet. We started out as payments infrastructure, and now we are helping businesses solve a whole range of problems. How do they accept recurring payments like subscriptions? How do they do usage billing, revenue recognition, tax, money movements, accept stable coins, and more? And when you think about what we’re looking at, we’re looking at on the order of 1.3% of global GDP. About $1.4 trillion a year is processed on Stripe. And so that obviously creates a very unique opportunity to use that data to understand both what’s happening in the economy. What do our users need? But also feed it back into the product to power better payments experiences, so cut down on fraud, drive the right authorization, better customer-facing experiences, optimizing the checkout suite, and more. So anyway, our data and AI org is just really focused on helping Stripe make effective use of our data. And that starts sort of all the way at the foundation layers, right? Like, what’s the data platform? How do we do data engineering? What are our ML infrastructure, AI infrastructure? And then all the way up to the technology. And then all the way up to the applied layer. We also have a fun little group. It’s actually quite small. It’s just two dozen people, but we call it the Experimental Projects Team. And it’s not data-specific, but the premise is experimentation can and should and does happen everywhere. But there are often these sort of cross-Stripe opportunities that are being pulled out of us by our users, just given the pace at which the world is changing, that aren’t natural or easy to jump on within any one product vertical. And so these are just quite senior, quite seasoned engineers who run at those opportunities and zero to one them and get them off the ground. So our agentic commerce work came out of that. Token billing, which we can talk about in a bit, also came out of that. And that’s just a fun sort of side angle within our group that’s proven very high leverage.
Swyx [00:02:18]: Yeah, I like the framing that Stripe’s mission is build financial infrastructure for the Internet. And your subset of that is build economic infrastructure for AI. Yeah. And that’s a pretty...
Stripe’s AI Journey and Investment in Foundation Models
Alessio [00:02:30]: Ambitious goal. You’ve been at Stripe four years. At what point did AI become a title-level thing? Because, I mean, you were obviously using machine learning for fraud detection and everything. You were at Coursera. Yeah. Yeah.
When AI became a title-level focus at Stripe and early ML/AI applications
Emily [00:02:43]: We started investing in AI or LLM-specific experiences basically when GPT-3.5 hit the scene. We were like, okay, we need everybody to be able to have high-quality, safe, easy... ...access to LLMs, not just for their own, you know, day-to-day work usage, but actually to build, you know, production-grade experiences. So that’s sort of, what was that, early, like, January 2023 or late 2022. We started reasoning about, okay, like, you know, it’s not just ML infrastructure. It’s also AI infrastructure. It’s not just ML applications. It’s also AI applications. But then it was really only in the last year and a half or so that we said, hey... I mean, we had, like, transformers and whatever before. But only in the last year and a half or so that we were like, hey, we actually need to have our own domain-specific foundation model. And actually, we can move from these, you know, single-task, point-solution ML models to, you know, a much richer, denser payments embeddings that can then power the various downstream applications. So I think it was an evolution for us. And, you know, I think we could still debate, like, what’s ML and what’s AI in the industry at large. But you’re right. We’re more than a decade into using ML at Stripe, you know, way back in the early days for not just radar, which I think people know about, right? Like, the machine learning systems that block fraud for our customers, but also ML internally for our own operations. Like, every other payment service provider is onboarding max a dozen users a day. We’re onboarding thousands of users a day. And you have to make sure they are supportable and not fraudulent. And are creditworthy because you are processing their transactions. And that alone requires machine learning and long has. Yeah.
Detecting Card Testing Fraud with Foundation Models
Swyx [00:04:37]: I would say, you know, it’s kind of interesting how the domain-specific models first come up, like, pre-foundation models. And then we have this foundation model era. But then at the scale of Stripe, I imagine that you also have to just serve in so much volume of inference that then you might have to domain-specialize them again. Yeah, so there’s fine-tunes on top.
Foundation models and card testing fraud detection
Emily [00:04:59]: There’s fine-tunes on top. I mean, we see, like, 50,000 transactions a minute.
Swyx [00:05:05]: But not all of that goes through your foundation model.
Emily [00:05:08]: Yes, every single transaction. So, for example, the foundation model, one of the things it powers is detecting card-testing attacks. Do you guys know what card-testing is? Yeah. Yeah, okay. So, for listeners, it could be, like, a card tester could be enumerating through cards or they could be random-guessing cards. They find a card that works and then sometimes they use it for fraud. More often, they sell it. Lots of traditional machines. Machine learning models can do a pretty good job detecting card-testing. But card-testers have gotten clever. And one of the things they do is that they hide their card-testing in the volumes of very large businesses. So, if you think about a very large e-commerce company, you can think about how many transactions are there. A card-tester might sprinkle, like, 100, 200, 3, 4, 5-cent transactions in testing. Traditional ML is, like, not going to catch that. Then you have a foundation model. Each, you know, charge becomes this, like, dense embedding. You start to see these clusters sort of pop out and you know in real time that they’re card-testing and you can block them. So, yes, it is happening on the charge path in less than 100 milliseconds of latency.
Alessio [00:06:15]: Have the foundation model enabled more data to be put in the embedding? I think, like, you know, things like, you know, number patterns and, like, zip code versus, like, location. I think those you could do before. Are there any new data points that you get? Yeah.
Embedding Payments Data and Behavioral Sequences in AI Models
Emily [00:06:28]: So, I think there’s... I think there’s two big things. Like, one, you know, when you’re building a small model, you’re usually, like, oh, looking at the data that, like, has reasonable labels. It’s, like, recent history. You probably have some, like, hand-engineered features in many cases. If you’re actually, like, building an FM and you’re imagining there’s many downstream use cases, you’re putting, you know, tens of billions of transactions in it. You’re putting, like, the entirety, like, every detail of the payment in it and letting the FM run. And you’re putting some reason about what are the components that matter versus not. So, it is literally all the things. But I think what’s even more interesting is, like, the last K. Like, what matters is the sequence. You can think of a payment sort of like a word. And so, you can think of payments data kind of like language data. And what matters isn’t the word, right? It is the word in relation to the words around it. But what’s tricky about payments is you don’t see, like, you know, Emily on a podcast saying 20 words. And no, those are not 20 words. Like, the sequence that could matter could be, you know, this particular retailer charges from this IP. It could be anyone on a Friday night with this credit card. And so you kind of have to choose a broad swath of relevant sequences to capture kind of the last K that matters. So if you think about like a movie, right, like what are the scenes in a movie that you need to be watching to know if there’s something anomalous happening?
Swyx [00:07:57]: Yeah. And for listeners, I think you’ve talked about this in a number of places. The card testing detection numbers went from 59 to 97 percent.
Improving Fraud Detection and Identifying Suspicious Transactions
Emily [00:08:05]: Yeah. On large users. Which sounds pretty helpful. It was really helpful. But the other thing that was really helpful was like the speed at which we got it out. Right. So like we had a couple of the large AI companies came to us and they said, hey, this is like after card testing, they’re like, hey, radar is amazing for finding fraudulent disputes. And that’s what it’s that’s. That’s what it’s trained on. Right. Transactions that result in fraudulent disputes. But we have all these sus, like suspicious transactions that don’t result in fraudulent disputes, but we still want them flagged. We want them flagged because even though they don’t result in a fraudulent dispute, even though we get paid for them, like they’re bots, it’s not good traffic, like they’re messing up our numbers, all sorts of different reasons. We can talk about some of the fraud that AI companies are facing. And so we want you to send us a pipeline with all the sus transactions, even if they’re going to be revenue generative because we’re probably going to want to block them. And it was like literally days like, OK, like FM embeddings, clusters, you know, good textual alignments. You can start to label them and you’re like, this is the clusters, you know, that look sketchy because they are enumerating some component of the login flow. These are the these are the ones that look sketchy because they’re enumerating some components of the login flow. These are the ones that look sketchy for X, Y, Z, other reasons. And then the AI companies could literally say, OK, this batch we want to block this batch. We don’t. So it just allows you to move faster on identifying not just new fraud vectors, but like whole new types of suspicious transactions.
Alessio [00:09:35]: How has the scale changed with AI? So before, you know, I used to run some software website and we would have the same issue. People buy the software and then gets charged back. But it’s like 20 bucks. Like today, you could like, you know, use the credit card and sign up for the OpenAI API and spend $10,000. $15,000. Like what’s the shape of the fraud today?
Friendly Fraud in AI Companies and Its Economic Impact
Emily [00:09:55]: So friendly fraud is like not stolen card credentials, but something like nonpayment abuse, free trial abuse, refund abuse. So it’s me. There are my credentials, but I’m not actually creating a creative revenue for the business. This has happened for a while. And actually, if you if you ask business leaders like I think something like 47 percent payments, there’s like 47 percent of them will say that their biggest. Fraud challenge is friendly fraud. I would say this was like just much less of an issue for SAS for two reasons. One, like what were you stealing? You weren’t stealing computer inference or whatever. And two, more importantly, even if you were stealing some service, like the marginal cost of providing that good or service for Salesforce or whomever was like near zero. And so it didn’t totally crush your unit economics. Now we’re in the world where GPUs are expensive. Inference costs are high. And free trial abuse. Free trial abuse or refund abuse or general nonpayment abuse. Right. You you rack up these charges and you never pay is like existentially threatening for AI businesses. I was talking to a small AI founder the other day because we’re building sort of a suite of radar extensions that are explicitly targeted at this type of fraud. And everyone tells me it’s a huge issue. And so with every company I talk to, I try to dig in on for you. What exactly is the issue? And there’s the first guy who told me it’s not an issue. And I was like, oh, fascinating. What are you doing? He’s like, well, I. I completely shut down free trials and I dramatically throttle credits until you’ve proven ability to pay. And I was like, well, you don’t think fraud’s an issue, but it’s like totally like you’re choking your own revenue. Right. So anyway, we worked with it. We got free trials back on. And that’s that’s in flight. What’s interesting. This is definitely a problem for AI companies because of the marginal cost. But it’s not only a problem for AI companies. If you think about like advertisers. Right. If you’re like you’re like a social media platform. Right. Advertisers come in, you let them start advertising. They do post hoc billing. Right. So you rack up some spend and then you pay. And if you don’t pay, that actually is expensive. Not because you’ve sold on compute in this case, but because you’ve taken ad slots from businesses who would have paid. Fascinatingly, I don’t know if I should mention. I think I could say it. OK. So my friend got a Robin Hood credit card the other day. Yeah. And literally as part of getting the Robin Hood credit card, he was marketed that he could also get. Free trial cards and I was like, oh, tell me more. What are free trial cards? Free trial cards are basically like cards with your name on them that are good for 24 hours and then expire so that you can sign up for free trials without ever having to get charged. So in the hands of a well-meaning consumer, that sounds fine. In the hands of a fraudster, that’s like extremely disruptive to the AI economy. We just announced our free trial offering. We can catch the majority. We can catch the majority of free trial abuse at the source. We’re working on the analog for refund abuse. One of the places where refund abuse is really painful, you mentioned this in the context of large volumes, like some of these AI companies will have like enterprise grade plans where it’s like $600 or $1,000 or $10,000 a month for hundreds of thousands of credits in whatever units they’re providing. And those are the ones that are getting hit with refund abuse. So a lot of the free trial abuse is like the consumers, the little dollars, but it adds up. But a lot of the refund abuse. is like very, very large subscriptions. You use it in full and then you go and cancel. And we see the usage happening. So like, and we can verify that it’s the person. So there’s a lot we can do here. And I think we can burn it down, but it’s like clearly creating a lot of pain for the ecosystem today. And just that vignette of that founder who told me he’d solved fraud. I just, you know, I think that just speaks to like, it’s so painful. They will literally give up revenue to not have to deal with it.
Extending Stripe Radar for AI Business Models
Swyx [00:13:49]: I think you teased a little bit. About how you’re extending Radar to serve new AI business models. And I think Stripe in general, I think is interested in like enabling payments for, for these AI business models. But basically like what, what do people want and maybe what’s realistic versus what is not realistic. I don’t know if that’s a term.
Stripe as Economic Infrastructure for AI Startups
Emily [00:14:10]: For sure. So, you know, I think of Stripe as like the skeletal system for AI companies. So if you look at the Forbes AI 50. All of the. All of the Forbes AI 50 who monetize online, monetize through Stripe and what do they use us for? You know, most of these companies, I mean, you’ve seen it with like the, the cursor and lovable examples, right? They build these very scaled businesses with very lean teams. And so they want to go like all in kind of on Stripe to get many layers of the sort of economic infrastructure, financial infrastructure stack in one go without needing to hire humans to do it. So they use us for payments. These. They use us for payments. We were looking at the top hundred grossing AI companies on Stripe. And like the median was in 55 countries at the end of their first year and over a hundred countries at the end of their second year, which is like twice as global as the SAS wave from three years before. So they, they almost all adopt our optimized checkout suite, which comes with a hundred payment methods out of the box, very global reach. They almost all adopt radar and our fraud suite. And then one of the things that’s been really interesting is, you know, I think the, the market’s still trying to figure out what’s the intersection between supply and demand. And so there’s a lot of iteration across monetization models. Like, is it a fixed fee subscription? Is it pay as you go usage? Is it this credit burn down model? And there are revenue implications. There are also fraud implications, but equally important. There’s like unit economic implications. And I think one of our recent ahas was, you know, as the LLMs have gotten better, more and more AI companies are rappers and I don’t, I don’t say that in a, sorry, rappers are not an R and I don’t say it in a derogatory way. I say it in the same way, Arvind Srinivas once said to me, like, I am proud to have started as a rapper, product market fit and build an amazing product and move really quickly and not get slowed down in the research and other people could provide the underlying models. I could do that later if I wanted or not. But yeah. But because a lot of these AI businesses are rappers, right? Their services have an inherent LLM cost underlying them. We know that LLM model providers are ebbing and flowing. The underlying models are getting better or worse. The price of those models are getting better or worse over time. And so that actually leads to a lot of complexity in how you price your final service. When that final service is like so dependent on an upstream LLM. So one of the things we launched two weeks ago now, we call it token billing, but it’s basically you, it’s an API that lets you track and price to inference costs in real time. And what does that do? It’s like, well, if, if your service is built on underlying LLM and the model cost drops 80%, which we’ve all seen it happen, right? You don’t want to keep your price where it is because the competition is going to swoop in. But then conversely, and I think more threatening if the, if the cost of the underlying LLM three, Xs, which it also sometimes does, surprisingly, you could have unit economics that are literally underwater if you don’t, if you don’t adjust your price. So, um, you know, token billing is an example, but, but we’re seeing these AI companies, you know, iterate across usage-based billing, outcome-based billing is kind of an interesting one.
Token Billing and Real-time Inference Cost Tracking
Swyx [00:17:29]: Does Stripe get involved there because that’s not really within your normal wheelhouse.
Emily [00:17:34]: We do. So our, we have, so we have payments and then we have a billing suite and almost all the AI companies use our billing suite. Billing includes. It includes things like fixed fee subscriptions, but it also supports usage-based billing. So like metered billing, um, and you can define usage in all sorts of different units. And we have a number of customers, including Intercom who actually define it in terms of the outcome. So in this case, it’s like support cases, resolutions, exactly. And, you know, I, I think it’s really interesting. I’m an economist by training. I told you earlier in the elevator that I think physicists make the best, uh, scientists or MLEs, but I didn’t know that at the time. So I’m an economist. Um. And I think a lot about, okay, like what makes the market efficient or inefficient. Um, and one of the things that I worry about in AI is it’s incredibly hard to take a product to market when someone has to pay for it before they see the value. Um, and that’s especially true with AI because a lot of the buyers, especially enterprise buyers don’t understand how to evaluate the underlying technology. And so if you can get your foot in the door by saying not just, oh, you’ll only pay for what you use. I mean, pay for what you use. I mean, pay for what you use is kind of helpful because they’re not committing upfront to some huge contract, but they can come in with a fear like, well, what if my employees use it a lot and it’s not actually helping the business. And if you can come in with like an actual cost sort of pricing function that is clearly profit positive for them, um, it’s a lot easier to get your foot in the door, right? So, you know, that a human resolving a support ticket is X, I promise that I will charge you, you know, less than X, like it seems conditional on quality strictly better. Uh, for you to try out my service than not. So anyway, we see, we see a lot of outcome based billing. The other thing we see an interesting amount of from AI companies is stable coins. And this one’s, this one’s earlier, but their use cases are interesting. So like if you, if you go to V zero now and sign up for an account, you can actually pay, uh, in stable coins. We’re seeing this a lot for AI companies that want to have very global reach, but also for AI companies that have very high price points. So like shade form, the, the YC star. Up is a great example. Um, they accept stable coins. Stable coins are now actually like 20% of their volume and their use case for stable coins is basically like very global and very high cost. And so the global means ACH isn’t an option, right? ACH is usually what folks in the U S would go to for low costs. If you’re going to use something like, you know, international cards though, on like a very large basket costs, you’re talking about paying four and a half percentage points, literally. Just to international card costs. And so that’s just taking a bunch of your margin that you don’t, that you don’t want to give away. So now 20% of the volume comes through stable coins. We actually did an experiment with them and half of that is fully incremental, which is to say they would only have 90% of the revenue they had, had they not opened up stable coins. The other half is a shift from other payment methods to stables. And then on the cost side of the house, you know, the cost of stables for them is like 1.5 percentage points versus 4.5 percentage points. So that’s a couple extra percentage points. So stable coins is another thing that we’re seeing AI companies adopt pretty quickly. I like to say that nerds buy from nerds and so there’s a nice sort of network effect there, right? Like if people who use AI have stable coin wallets, when they go to the next day, I provide her, they have a stable coin wallet, right? It’s sort of self-reinforcing. We also see this with link, which is our consumer product. Like link just passed 200 million consumers. So it’s not a small network. But what I think is more interesting is in the case of AI, it’s a very, very dense network. So lovable accepts link 58% of lovable’s volume flows through link. So for every three people who are buying on lovable, two of them are buying with one click link checkout because they already have a link account. And I think that just like gives you a flavor of, of the density of the link network, but also the density of the AI network. Yeah.
Adoption of Outcome-Based Billing and Stablecoins
Swyx [00:21:37]: Is there a, are there classical measurements of network? Is there a network density that you keep an eye on, even though it’s obviously as an economist, like that’s the first thing I go to. Yeah.
Emily [00:21:46]: Um, I mean, the Herfindale index is less about network density in particular, and more about, as we look at all of the transactions that are flowing through Stripe, how concentrated are they on? I mean, you can look at it along a lot of dimensions. You can, and merchants, how concentrated are they on certain merchants versus spread across merchants? Yeah. How concentrated are they on certain industries versus spread across industries? How concentrated are they? How concentrated are they on certain geos versus a broad range of geos? And yeah, we definitely track that concentration. Now for us, some of that is actually the inverse of network density, which is we want diversification, like, you know, um, and we want to be exposed to many different industries and many different markets and have global reach because the current wave is AI and I am incredibly bullish on AI, but we really want to be growing the GDP of the internet broadly. And that’s not constrained to only the AI domain. Yeah.
Swyx [00:22:38]: Um, excellent. Should we, uh, move into the ACP? Uh, I don’t know how to transition it better than that. I agents do want to eventually do commerce between themselves. I guess that’s the transition and that, that, that, uh, is that the perfect intersection of financial infrastructure and AI. So maybe, uh, could you tell us the story of ACP, right? Like, I think, uh, this is one of the, the, the biggest launches of, I guess, like in the, in, in, in the second half of the year and, and like, I guess a really important strategic move between OpenAI and Stripe. Yeah.
Introduction to Agentic Commerce Protocol (ACP)
Emily [00:23:09]: So, you know, we talked a bunch about AI companies in general. One important slice of AI companies is AI commerce, agentic commerce. And, you know, I think just zooming back, like we’re all spending more and more time in some combination of broad consumer-based tools like ChatGPT and AI dev tools like Replit or Vercel or whatever. Right. Right. Right. Right.
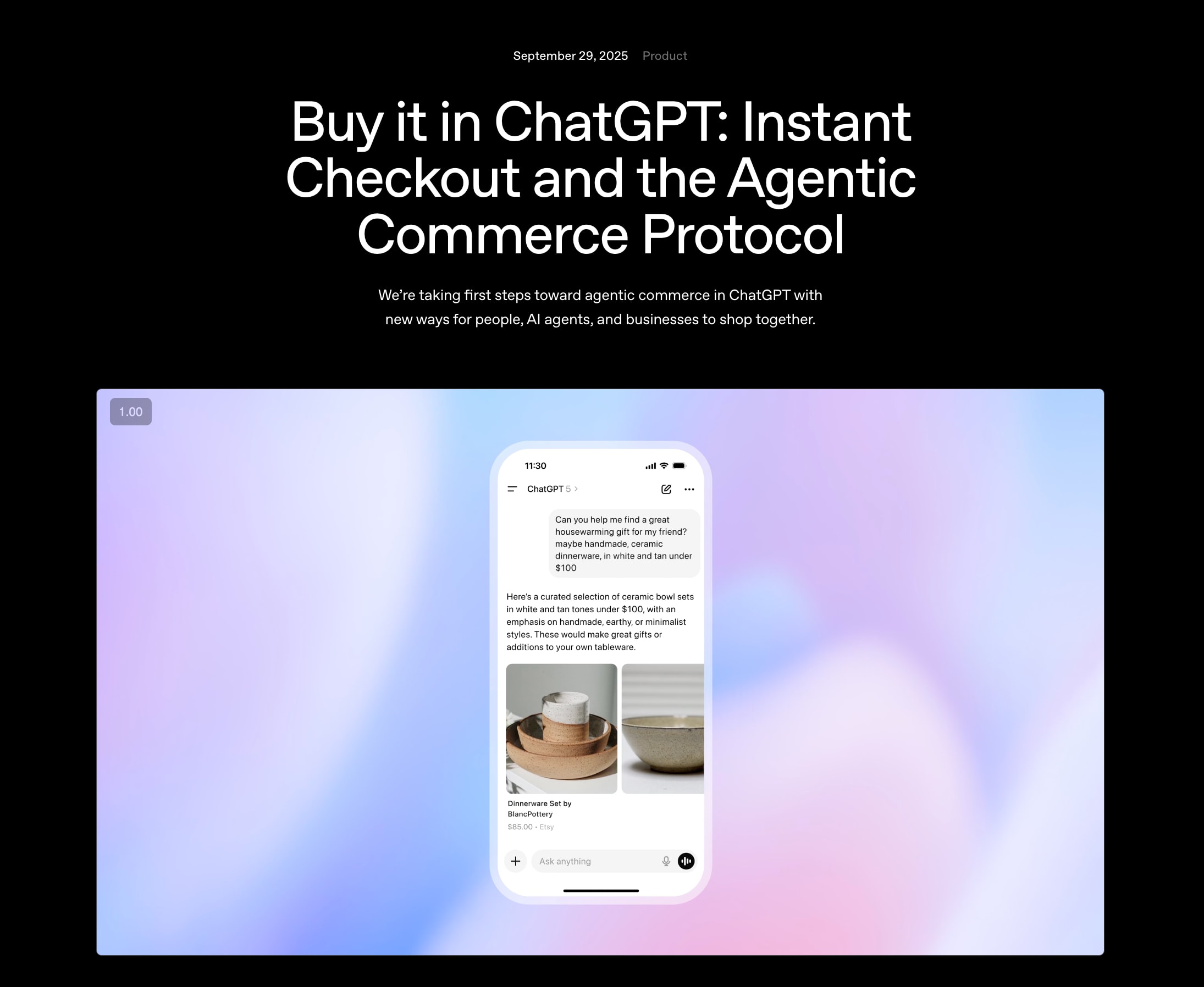
Emily [00:23:43]: And I think, you know, we saw an early version of this in ChatGPT with Operator, but an important area we want them to take action is buying on our behalf. You know, sometimes it’s recommending products, but often it’s like literally getting it all the way over the wall. So, um, a couple of weeks ago, we announced our agentic commerce protocol, which is joint with OpenAI, and it’s basically just a shared standard for how businesses can talk. So if you think about it, like it used to be that a human was buying from a business, now there’s an agent that’s sitting in the middle and that fundamentally needs to change how the financial infrastructure works, like checkout needs to look different, fraud checks need to look different, payment flows need to look different, but also merchants are trying to figure out how they can efficiently expose their product catalog, their inventory, their brand, their pricing through a range of agents to have access to their products. So it’s kind of a brave new world. So the agentic commerce protocol is really about that shared language for agents to get from merchants what products they have available at what prices, how they want the brand to appear. And then we also built a shared payment token, which basically allows the agent to pass over the required payment credentials on behalf of the buyer, because the agent doesn’t want to bear the risk. The agent doesn’t actually want to be in the middle of the transaction. And the merchant wants to, you know, undertake the charge and actually have the direct relationship with the consumer at the end of the day for returns and more. And so the shared payment token was also an important component. And then fraud was another important component, right? Is this a good bot or a bad bot? There was a day not very long ago when the optimal thing to do as a business was to block all bots. Now, many bots are good bots. You do not want to cut off that demand. And so what we pass over as part of the shared payment token includes scores on the goodness of the transaction so that the merchant can make the right decision. One of the ways this manifested was an instant checkout in ChatGPT. Have you guys bought anything from this?
How ACP Enables Instant Checkout with ChatGPT
Swyx [00:25:55]: Not yet, honestly. I’ve tried. It just recommends things, but I always want to take over the last mile of checking it out myself. It’s hard for me to, like, hand over control.
Emily [00:26:05]: Okay, yeah. And I think they’re also still, like, iterating on their recommendations. To some extent, last night, my daughter was at a class, and so I took my son out to dinner, and he told me he has a school play, and he is supposed to dress as a Spanish shopkeeper. And so I tried to search for, like, kids’ Spanish shopkeeper outfit, and they recommended me a $1,300, like $1,300 bolero off Etsy.
Alessio [00:26:29]: The play is not that important.
Emily [00:26:31]: I love the child, but the play is not that important. But there is a lot of great stuff you can buy. And so in the... In the initial Instant Checkout Lodge with ChatGPT, you could buy from U.S.-based Etsy sellers. There’s over 1 million Shopify merchants coming soon, including some really big ones like Glossier and Viore. This week, Salesforce announced that they’re also in. And then, you know, my favorite is that, like, a week ago, two weeks ago, you could have asked, hey, are the largest retailers going to get on board with this or not? In the last couple of days, Walmart and Sam’s Club have just signed up to also make their inventory purchasable through ChatGPT and the Agentic Commerce Protocol, which, like, I don’t think that there is a bigger signal on a big retailer being up for it than Walmart. The world’s biggest one, yeah. Yeah, yeah, yeah. So that’s pretty exciting. And then, you know, one of the things that is important to us and to the broader ecosystem about the Agentic Commerce Protocol is, is it’s not about Stripe. So that shared payment token I talked about or the Agentic Commerce Protocol, like, that works no matter who your payments provider is. We can pass the shared payments token over to any other PSP. You don’t have to process on Stripe. It’s also not just about OpenAI. And so in the same way that, like, you and I are seeing, you know, new models come online all the time, we want to be able to move across models flexibly, there’s going to be sort of new agentic buying experiences coming online. And we want to make it easy for merchants and kind of, like, one shot to integrate with all of the agents as they come online. And that’s what the ACP really provides, because it’s a standard protocol versus needing to do custom integrations per agent. Did you guys see Karpathy’s tweet about the, he basically, like, recreated…
Swyx [00:28:27]: NanoChat? Mm-hmm. Okay. Yeah.
Emily [00:28:28]: So, like, if he can do that, 8,000 lines of code, less than $100, like, you might think that a lot of companies are going to roll their own really soon.
Swyx [00:28:36]: Using NanoChat? That would be interesting. I haven’t made that connection yet. Let’s see. Let’s see.
Emily [00:28:42]: But I think this basic premise that, like, it may be a winner-take-all, but it’s not yet clear who the winner is. And by the way, like, I hope for the efficiency of commerce that it isn’t a winner-take-all. Therefore, many merchants need to actually be having their products sold through many agents is kind of the premise of ACP. And we’re just delighted to see the early traction. And, you know, have just been flooded, honestly, with both merchants and AI platforms wanting to join. So, I think we’re on the right path.
Swyx [00:29:15]: Yeah. And this is your protocols, kind of. Yeah.
Alessio [00:29:18]: We did an episode with Crunch AI, which does web rewriting for agents. And they have him as a customer. They have scams. And I think every brand is, like, I mean, for brands, it’s very easy. It’s like, hey, I don’t really care where it comes from. Yes. If you buy my thing, we’re friends, you know. And I think, like, you take away. You take away the part which is, like, the most annoying to think about, you know, which is, like, the fraud. I do have a question on, like, the good bots, bad bots when it comes to, like, scarce releases, like tickets for events and things like that. I think that’s going to be interesting. Oh, please, Salt Ticket Master. Oh, my God. Exactly. It’s like, well, but now if anybody can just have an agent that just goes on the website to buy them, now it’s like, how do you do the queue? Because everybody gets there instantly, right?
Handling Good Bots vs Bad Bots in Scarce Inventory Scenarios
Emily [00:29:59]: I won’t say the company, but I had dinner the other night with the guy who’s the CEO of. You can basically. You can basically think of it as, like, StubHub for Country X. I won’t say what Country X is. And he was selling, I think it was, like, 3,000 Bad Bunny tickets. And he had 400,000. Oh, my God. People come to buy the Bad Bunny tickets, except almost all of those people were actually bots. And this is a great example of what we were talking about earlier, around, like, it’s not just about the fraudulent dispute. So the conversation I was having, he was like, you know, we have scalpers. Scalpers who have bots. They end up scalping the tickets later. They come and they buy. It doesn’t result in a chargeback. Like, they pay, but they’re not the people that we want paying. And so to our conversation earlier on suspicious transactions, like, there are lots of different types of fraud. And thinking of fraud as just things that result in a fraudulent dispute is actually overly narrow. And he wants to block, you know, all the scalpers, everyone who’s, like, you know, enumerating through email addresses in their signup and, and, and. The other thing he said to me, which was interesting, is he. He, for various reasons, and some of this is actually, like, the, the, the nuances of how his system is built. But I think some of it generalizes. He wants to have those fraud signals before they even get to the checkout page. And so how can we understand the customer independent of them entering their payments credentials? And there are a bunch of ways we can, and we can get better there. His particular reason why is he’s got, this is a little mundane. But once the ticket goes into the cart, it can’t be touched for, like, 10 or 15 minutes. And so even though, you know, it’s successfully blocked at the actual charge time, it’s, like, been held from, from those, those other good customers. So anyway, I, I think there’s this, there’s a lot of exciting work to be done that’s actually, like, increasingly possible. Not just because of the scale of the Stripe network, but also because of AI around understanding an expansive set of fraud vectors. And, you know, if, if you think about traditional. Terministic systems, you know, you’d write rules like block, don’t block. Now you can think about, okay, actually foundation model, text alignment, like human readable description of like why we’re worried about this charge. And then today, a human, tomorrow, an agent sitting on top of that and decisioning, like reasoning over, the model outputs. Um, I think that’s the world we’ll be in, in the next three to six months. Yeah.
Using Foundation Models for Advanced Fraud Detection
Swyx [00:32:28]: I think we need to. We have to be careful about rolling those kinds of things. Yeah. Because people get very upset and justifiably so, and they’re denied something that they, they, they should have by a bot that won’t explain itself. Yes. Right. There needs to be like an appeals process or like something like tier two human, like.
Emily [00:32:45]: For sure.
Swyx [00:32:46]: Can I speak to the manager, please? For sure.
Emily [00:32:48]: And yes, for sure. And well, humans make bad calls too. Sometimes they make bad calls at higher rates than LLMs because they can’t reason over as much information, but I agree. Definitely appeals process. But then also like. When we actually look at. Bad actors, it’s like a tiny, tiny share of bad actors accounts for a huge volume. Right. You’re just rooting those out. Of the bad outcomes. Yeah. And so what ends up happening is actually good actors have worse experiences, which could mean they don’t have access to free trials or they’re gated and how many credits they can use prepayments or they’re just charged a higher price because they’re covering for the cost of the bad guys. Right. And I, and I. And I actually think there’s an opportunity to like, you know, I’m from Montana, so sometimes I talk about sheep and goats, although I don’t actually know which is good and which is bad. Separate the sheep from the goats in a way that’s like really good for the good actors.
Swyx [00:33:44]: Why are sheep and goats bad? Like.
Emily [00:33:46]: No, only one’s bad and one’s good. But I don’t know which is. Why can’t they both be good? That was like an idiomatic expression everyone used growing up to separate the sheep from the goats. And I’m like, I don’t know. But they’re both good. They’re both cute. I think sheep are supposed to be cute, but I’ve always been impressed. Have you guys been to Yellowstone?
Swyx [00:33:58]: Yeah.
Emily [00:33:59]: You go into Yellowstone National Park, like the mammoth entrance, and there’s this like sheer giant, you know, wall of rock. And there’s these mountain goats. The goats just chilling. Exactly. They’re like scaling it at 90 degrees. Yeah.
Swyx [00:34:10]: Like mountains I get, but like dams, I don’t know why they love dams so much. It’s like, it looks so dangerous. And like there’s babies just walking on there.
Emily [00:34:17]: So dangerous. Yeah. It almost looks like AI generated the image, but it’s real.
Swyx [00:34:21]: It’s real. It’s real. And okay. I’m going to do like economist corner just because like, you know, you clearly still identify as an economist.
Economic Decision-Making in Ticketing and Market Efficiency
Emily [00:34:29]: I do identify as an economist. It’s very strange. Yeah.
Swyx [00:34:32]: Yeah. Yeah. Well, so like when you encounter those, like the StubHub for X, don’t you feel the temptation to recommend an auction? Like, and there’s so many auction mechanisms that can clear the market. This is clearly a market clearing problem. What’s the market solution here?
Emily [00:34:46]: I don’t know that I am usually tempted to recommend an auction. I am usually tempted to ask a lot of very probing questions about why they’ve designed the system the way they’ve designed it. Yeah. Yeah. Whether there’s a, whether there’s a more efficient path, but yeah, I, I feel that way about, um, most, most pricing matching discovery recommendations. Like most markets are just inefficient. And so I think there’s a lot of opportunity to make it better. Um, one of the reasons I joined Stripe and one of the things I have loved about being at Stripe for the last four years is when we see those opportunities to make the market more efficient. Um, we can, we can actually invest in doing them without optimizing them, you know, without monetizing them directly. So you can think of it like incentives are very aligned. Anything we do to help the businesses on Stripe grow helps us grow because, you know, they, they run their payments through us. Yeah. Um, and so we do this all the time. Like, here’s how to, you know, improve your checkout. And we just like update the checkout for them or like optimizing their payments acceptance or automating their retries. Um, so anyway, I think it’s just, it’s, it’s very nice to be at a company where you don’t have to worry about the go to market for something that helps the businesses that run on you. You just have to help the businesses that run on you do better. Um, and that in and of itself is, is a good outcome for your company and justifies the investment. Yeah.
Swyx [00:36:15]: They’re very incentivized. It’s like top line and bottom line sometimes. Yeah.
Emily [00:36:18]: And by the way, like this isn’t all causal, but, um, last year the companies on Stripe grew seven times faster than the SMEs.
Emily [00:36:31]: And, you know, again, like not all causal and there’s selection effects, but definitely some of it, some good, some good tailwinds. Yeah.
Stripe as a Growth Engine for Internet Businesses
Swyx [00:36:38]: Yeah. So, I mean, yeah. And I think the economist term I really like is deadweight lost and like basically like eliminating friction. It means improving surplus for both producer and consumer and Stripe benefits as a result. It’s just like, that’s nice. Everyone wins. Uh, it’s a, it’s a good, good, uh, fuzzy feeling. Coming back to the protocol. I think that it’s an interesting decision to actually release it as a protocol. Like you said, it’s going to be many to many. And like sometimes Stripe is not involved. You also mentioned like Stripe link and Stripe checkout, and those are Stripe products, right? Those are, those are not protocols. So I think like it’s a very interesting and pivotal decision to choose to release it as a protocol as, as opposed to not. I was wondering if there’s like any internal debate or is any internal color about like the decision behind choosing a protocol. Yeah.
Strategic Decision to Release ACP as a Protocol
Emily [00:37:21]: Um, you know, Stripe has moved fast for the entire four years. I think it is accelerating and I think it is accelerating because customers, users changes in what the market needs, both what businesses need and what buyers need, um, in the world of AI is accelerating. And so new products, new solutions like ACP, like token billing are literally being pulled out of us. And what we saw was a hole in the market, like consumers, and we can talk about developers too, but like consumers want to be buying through ACP. Agents, agents are ready to buy for them. Merchants are ready to let agents buy on behalf of consumers. And yet the market can’t figure out how to make it work. And that’s not about Stripe. That’s about growing the GDP of the internet. That’s about making sure commerce can flow. And, you know, so, so there was no debate. It’s like the ecosystem needs this. Like we will pair with open AI to get it over the wall. And, and by the way, like, as I said, we’re early days, you know, ACP is seeing a ton of traction, but. If it wasn’t, or if something different comes out six months from now, like all we want is a shared standard. We don’t need to have like our name on the shared standard. I think it’s absolutely, absolutely the right thing, the right thing to be doing. You know, I have had folks ask me like, is agentic commerce, just a straight substitute for the commerce that’s already happening on the internet. Yeah.
Swyx [00:38:47]: It’s just like fancy APIs. Exactly.
Emily [00:38:49]: And I think the answer is it’s not a straight substitute. I think it is actually like expanding the aperture of what. What commerce will get done. And the first person to put this bug in my head was Dwarkesh. And when he said it, it actually like took me a second, like, I didn’t believe it, but I think it’s right, which is if you look at the share of income that is spent on consumption as a function of how much income you have, you see that high income people spend a much lower share of their income, low income people spend a much higher share of their income. There are many reasons for that. But one reason is the biggest cost to very high income people consuming is not the dollar cost. It’s the time costs of consumption. And so I’m very interested in how agentic commerce can open the aperture for spending by high income people because it’s removing the most costly or binding constraint, which was their time. And we’re actually then truly pumping incremental, not substituted, but additive dollars into the economy. And obviously, like, you know, for. Yeah, well, it results in sometimes buying $1,300 costumes and I would rather spend an hour than buy a $1,300 costume.
Agentic Commerce Expanding Consumption Capacity
Swyx [00:40:08]: Well, you know, just work a few more years to stripe. You’ll get it. So so I think one like there’s some I think interesting where I love protocols, you know, as a developer tools person, I’ve been I’ve been involved in designing a few of them, debating a few of them. What are the forks in the road that, you know, like someone else was like discussing? Something really strongly, and we decided against it, or maybe it’s still an open question. I’ll give you one and then maybe you can volunteer another. So the I mentioned that both Solana and Circle have sponsored my conferences before, and they’re also trying to be that build a protocol for agents and both of them actually give agents a wallet, right, as opposed to a payment token. And I think like having an agent with their own bank account effectively is an interesting choice. You didn’t go for that. So like, is that a decision factor or is or is there a different one that you want to focus on?
Design Choices and Future Extensions for ACP and Agent Wallets
Emily [00:41:00]: Let me parse two things. When I think of the commerce protocol, that’s primarily around what’s the standardized way that businesses expose their products and their inventory and their prices and their brands and make those available to agents to expose to the consumers and or to buy on behalf of the consumers. That really comes down to like, how should a product catalog be expressed? How should prices be expressed? I think the current version is like the bare bones version, and it will continue to evolve. For example, like you could imagine like from a market clearing perspective that the merchant should also be as part of that articulating the cut that they’re willing to give to the agent, right? Like, like a little bit. Yeah.
Swyx [00:41:48]: In a classic, like if the human agent, I give them a budget, like what their negotiation target is and what their max spend could be. Yeah.
Emily [00:41:55]: Yeah, exactly. And so in this case, I’d be like, okay, well, you know, whatever, the Bolero that I didn’t buy is a terrible recommendation, but they have many good recommendations, but that was a terrible one. You know, this costs $1,300 on Etsy, but, you know, I’m willing to give X to any agent who facilitates the transaction, either on top of or underneath the $1,300. So anyway, I think there’s going to be an evolution of like the various parameters that should be included. But like the, the basic set was, what do you have to be able to deterministically expose to an agent so that they understand what’s available and what representation of the product and brand and, you know, sometimes it’s size and number and whatever, like has to be made available to the agent and or the, the, the human that’s initiating in the first place. Okay. Okay. So shared payment token is a little bit different, which is like, okay, how do you actually get the transaction done? Like, how does the money flow? And even at Stripe, like that has been evolving. So shared payment token is, is what we built and launched and have in the background of the instant checkout implementation with ChatGPT. But a year ago, Perplexity launched a travel search and booking agent. Did you guys see this? Yep. That is also powered by Stripe. And there, the payment flows are a little bit different. So we have an issuing product, which allows you to issue virtual cards. And what happens in that sort of flow is the agent gets issued a one-time use virtual card to spend on your behalf. And, you know, people get very, get very jumpy about that. But I like to remind them that like, when I order from DoorDash, my Phil’s coffee, right? DoorDash is issuing a one-time use virtual card to the, for $6, believe it or not, to spend on my behalf there. And so now you’re just inserting, you know, AI agent instead of human agent. And in the same way that my DoorDash driver never saw my card credentials and couldn’t spend, you know, more than $6 and had to spend it in a constrained time window near my house, same thing for the AI agent in the Perplexity travel search and booking agent. And we still have agents doing commerce through Stripe. Using the virtual card implementation and their pros and cons. So I don’t think that like, it’s going to be all virtual cards, going to be all shared payment tokens. It’s going to be all agent wallets. I think stable coins will be an interesting direction. I think wallets in general will be an interesting direction. I think stored, stored balances will be interesting, especially as we’re talking about kind of micro transactions, right? So we’re talking a lot about buying like goods, buying goods are usually priced high enough that it’s worth sort of like a car. Card transaction type approach. But if you’re talking about buying AI or buying some inference or buying content, you want to be able to make 5, 10, 25, 50 cent transactions. And those are hyper inefficient in the card world. So I think agent to agent payments are going to push us a little bit to the next frontier here. But ACP, again, is like distinct from how the shared payment token works or how the money flows. And I think that will, A, continue to evolve just because the market needs are evolving and the technology possibilities. Are evolving, but B will also like also doesn’t need to be standardized in the same way.
Agent-to-Agent Payments and Microtransaction Infrastructure
Swyx [00:45:28]: What about the receive side? I guess, can my agent make money for me?
Emily [00:45:33]: Can your agent make money for you? Oh, I was thinking the opposite, which is like, I’d be happy to give an agent, you know, $3 to go out and do deep research for me. And so we’re trying to figure out how to enable that.
Swyx [00:45:42]: No, that’s research. No, I was like, you know, like spending, I think like there, we have a good mental model of how to spend, especially because we have human agents as well. Yeah. Because. How to spend, uh, making money is, is, is obviously the, the original draw of, of, of, uh, strive for any, any founder. Yeah. Uh, yeah. I’m just kind of curious. What’s, what’s your thinking there?
Monetizing AI Agents and Claimable Sandboxes
Emily [00:46:02]: We make it easy to monetize your MCP server. So that’s like one thing. We also are seeing an increasing number of new businesses get going in AI dev tools like Replit and Vercel. And so we want to make it really easy to spin up monetization also within those tools and within that flow, not be taken out of flow and go and create a Stripe account. Authenticate and whatever, um, a couple of weeks ago, we released claimable sandboxes. Have you guys seen it? We’ve been in Vercel and seen it or no.
Swyx [00:46:30]: I know that you have a sandbox product, but I don’t know about.
Emily [00:46:32]: So we have a sandbox product, which you’ve seen from like being within the developer experience on Stripe. Now that sandbox product can be like invoked, used, manipulated. You can create your products and your pricing and run test charges and generate customers. And in that sandbox. Before you even. Have a Stripe account, or maybe you have a Stripe account from your last business, but before you’ve linked it to this business, right. And, and we call them claimable sandboxes and Vercel and Replit were actually remember talking to Replit at Stripe sessions in May about our sandbox product. And they were explaining to me how, um, you know, people are trying to build businesses end to end. And like one of the wonky parts of the flow is setting up the payments integration and get going. And so we started talking. About like, okay, could you actually have like the sandbox environment there? Um, and it was whatever, four months later and they had it, they launched it. We launched it with them. And also, um, with Vercel, actually Guillermo had a cool post a couple of days ago that, um, our Stripe integration is now one of their top. I think it’s like the third highest, uh, integration that they’re seeing in V zero. Um, and we’re only two weeks into the launch, but it’s basically like all of these people aren’t going to create. V zero just for fun to create something, just a website or whatever, just for fun, they’re going to create a business. And so making it really easy for them to do the business payments back end part of that and how it actually works is literally like you’re right there in V zero and you, you know, you have your plant shop and you create your products and you set your prices and you run your test charges and you click a button at the end. Like when you like what you see, you can go back and iterate later, but you click a button and your tab opens in Stripe. And you can either sign into the account you have or create a new account and you claim that sandbox and that sandbox, you can take it live and it becomes your business. And lots of people are taking it live every single day. And we’re seeing new businesses get created, um, that were never before. And one of the things that’s really fun to see, I was going through the list of businesses. I probably can’t name them live, but like a chunk of them are AI companies, like a chunk of the startups being created today are AI companies, but a chunk of them are like non-technical founders who may have actually struggled. Like. Get going on Stripe had they not had it kind of within that V zero. Yeah.
Swyx [00:48:55]: Low code is a huge enabler.
Emily [00:48:57]: Low code is a huge enabler. And, you know, we’ve, we’ve done some good work in our own onboarding experience to make it low code and we have, you know, low code subscription and whatever. Um, we have our, our new onboarding experience internally, we call it future onboarding experience and it kind of walks you through what’s the business model you’re trying to create and then sort of, um, stands up the sandboxes for you. But what’s cool is now you do a bunch of that in say V zero, if you’re in V zero, and then you come over. And, and your future onboarding experience has already learned like your intent and your preferences and all of that from Vercel. And so you’re dropped in X percent of the way through, uh, with the sandbox already spun up.
Low-code Tools and Future Onboarding Experience
Alessio [00:49:32]: So this is like from the outside, how people perceive AI as Stripe. What about inside? So you mentioned 3.5 was kind of like the moment you took it seriously. What were the first internal use cases and then how do you use AI Stripe today? Yeah.
Internal AI Adoption at Stripe and Early Use Cases
Emily [00:49:45]: First internal use cases were, you know, bottoms up experimentation, right? So we created, we call it go LLM, but it’s like just a chat GPT, like interface where you can engage with a bunch of different models. Um, it was the very, very first version actually wasn’t like an LLM proxy where you could build production grade systems. It was literally just like chat GPT like stuff. And then we had this like preset feature, which was like prompt saving and sharing. And so you could share your tempo. Oh, you know, this is how I figure out what customers to reach out to and generate reach outs or, um, you know, rewrite. My marketing content in Stripe tone or whatever. And you had sort of hundreds of presets that came on like overnight because everyone was into it. And then we generated, so then LLM proxy was like, okay, now production grade access for engineers to these LLMs. And a lot of the early use cases there were actually around merchant understanding. So I mentioned a little bit ago, but we have like thousands of merchants that come on to Stripe every day and we have to understand who are they? What are they selling? Is it supportable through the card networks? Like, are they credit worthy? Are they fraudulent? Um, and there’s a. Lot that LLMs can do there. So those were some of our earlier, um, earlier use cases. Fast forward to today. I mean, you know, I, I actually was looking at the dashboard earlier cause I was planning for, for 2026 and some of our LLM costs, 8,500 stripes a day use our LLM based tools. Okay. There’s like only 10,000 stripes. Like not everyone is in every day. Like it’s basically, it’s basically everyone. Um, and you know, I think people are getting like pretty creative in, in the. Um, I was talking last week to the LPM teams, the local payment methods. Um, you know, you and I think a lot about cards or whatever, but local payment methods matter because the businesses on Stripe are almost always selling internationally. And when you’re in other countries having local payment methods, you know, Jiro pay if you’re in, um, yeah, I’m from Southeast Asia. Yeah. It’s all over. What’s your favorite?
Swyx [00:51:45]: Uh, well, I know. I mean, uh, there’s like grad pay, I guess. I don’t know. Yeah, exactly.
Emily [00:51:49]: And like, if you don’t. If you don’t see a local payment method, like if you only see a card, you might not have cards, or if you only see cards, you might not feel like it’s like localized to you or meant for you. Whereas if you see like in market regional payment methods, you feel much more connected. You’re much more likely to convert statistically. And oftentimes the fees also, uh, make more sense, um, for, for the merchant. So we’ve invested a bunch in integrating local payment methods. Most businesses on Stripe use our optimized checkout suite. Our optimized checkout suite comes with over a hundred payment methods out of the box. Right. Right. Right. Right. Right. Right. Right. And so, you know, what is the, the challenge? The challenge is integrating with any new payment method. And it takes like two months for a couple of engineers. It’s not the end of the world, but Stripe’s a pretty lean company and we got a lot of stuff to do. And so, you know, for the marginal payment method, is it worth it? Yes or no? Well, when you step back, what are you doing? You’re really like looking at Stripe’s code base. You’re looking at like how the LPM works. And like the integration guide for the LPM, and you’re kind of like hooking the two up. And so the LPM team, it took them two weeks for the first one, but they just launched a new pan-European payment method in two weeks using an LLM to like build that integration. And I think they’ll probably, you know, have it down to a day or two within, within a month. And so that’s just a good example of like, it’s kind of should be just like a machine talking to a machine and there’s pretty good documentation on both sides of the house. And so the LLM can make it. It can make it pretty far. We also use a lot of AI coding assistance and yeah, I would say like 65, 70% of engineers use them on the day-to-day. I have a really hard time understanding impact. Like I don’t quite know what statistic to look at. I don’t actually.
AI-Assisted Integration of Local Payment Methods
Swyx [00:53:39]: It’s not lines of code. It’s number of PRs.
Emily [00:53:41]: I don’t think it’s lines of code because I have in the last week been sent three different documents. Yeah. That I know were like at least partially written by an LLM documents, not code. And in all cases, they went back to the individual and I said like, I actually just want to see the bullets that you put in chat GPT or whatever. Not the, not the eight page document because I have a really hard time reasoning about the eight page documents and it sounds good, but I’m not quite sure it’s like connected to reality. And I feel the same way about lines of code. Like, I don’t really want more lines of code, just like I don’t want more pages of docs. Yeah. Yeah. So we’re watching that. And then also the costs of a lot of these coding models is actually like pretty non-trivial. And so as we’re planning forward to next year, we’re reasoning a bunch about like, where can we get somewhat more efficiency there given like, obviously it’s valuable and we want people to be using AI coding tools for sure, but, and we want to make sure that, that we’re getting the right returns for the business. And some of that is managing costs. And some of that is getting a clearer read on impact. Yeah. Because we’re just starting to get that value. Yeah.
Measuring Productivity Gains from AI Coding Assistants
Alessio [00:54:46]: How do you feel the social contract is changing? Like you mentioned, just send me the bullet points, right? It’s like I could have sent you the bullet points before LLM’s but you are making me write this memo, right? I feel like in a lot of organizations, there’s like a performative and part of it is like, you know, wearing a suit to an important meeting. It’s like, in a way it’s like, hey, I’m doing it.
Emily [00:55:04]: I don’t wear suits. I don’t wear suits. I hear some people do. Yeah.
Alessio [00:55:06]: You know, I’m doing it to show you respect. And in the same way, I could have just sent you this bullet point. So we’re going to have this meeting in shorts. Do you feel like with AI now, it’s like, okay, if you’re going to do it with AI, just send me the bullet points and we’re kind of like breaking through in a way.
Changing Organizational Norms Around Documentation with AI
Emily [00:55:19]: Yeah. So that’s really interesting. Okay. So I hadn’t thought about this before, but here’s my working hypothesis. Tell me if it tracks. What I care about is that the expert in the area, like they’re an expert in the area. Otherwise they wouldn’t be sending me a doc, right? The expert in the area has thought deeply. And what is writing, like actual writing, typing, whatever, it doesn’t matter. But like writing not with an LLM forced you to do, it forces you to think deeply. It forces you to structure your reasoning. I don’t know about you guys, but when I read a doc, when I write a doc, I’ve like read the doc like 50 times and thought about like, does this logic track? Are there gotchas I’m not considering? Like, is that the train of thought? Like, how might somebody else, look at this? And it’s not like that I wrote the doc to be performative and the bullets would have been better. It’s that the careful, thoughtful, arduous, time-consuming construction of the doc forced me to appropriately reason from first principles. And I think LLMs do the opposite. Like, oh, you just throw in the bullets. You don’t have to reason from first principles. And it sounds good. And people like, but I think that’s extremely dangerous.
Alessio [00:56:28]: I think that is true. But I feel like you, you still are not generating documents with AI. So because you are the type of person that uses the writing as the thinking, you still go through the process versus the people that use the AI still wouldn’t put that much thought into writing the long document anyway. I think to me, that’s really the thing. Same way we were talking about this for code yesterday in another interview, which is like the slot machine effect of like cursor and like these tools. But at the end of the day, you got to merge the PR. So you got to come up with something that makes sense for the business. Like with these documents, it’s kind of like, oh, I don’t know. I don’t know. I don’t know. It doesn’t, like, you just need to come up with the right ACP design. I don’t care if it’s 10 bullet points or like 10 pages. To me, I think like things are changing now because also people read more summaries. So it’s like, well, if you summarize my thing, then why should I write a long thing? I should just write a short one. So, I mean, I don’t have an answer. Just like interesting to
Emily [00:57:19]: see how, you know, you’re like, just send me the bullet points. Yeah. The primary thing that I, well, there’s many things I care about, but like a very concrete non-negotiable is LLM was used in the generation of this content. Please cite the LLM. Because my least favorite thing is to be like two pages into what I think is a thoughtful doc
LLM Usage Transparency and the Importance of Critical Thinking
Swyx [00:57:40]: and find the annoying, like space, double dash, space. And then as a double dash guy, I feel like
Emily [00:57:47]: I was writing it before LLM’s ruined it. No, that’s not what tips me out. That’s the only thing that tips me out. But you know what I mean? Like, I do think we all need to be careful about LLM slop. And then I think there’s like a societal behavior. Behavioral thing here too, which is like, we can’t turn our brains off. I mean, I actually think that like, what do LLMs make all the more important in the world? The ability to think and reason deeply. To like question, to like tell the machine what to do more so than like to do and execute the task because the LLM can do and execute the task. And so if you’re looking at LLMs and you’re like, oh, that means I don’t have to think deeply because they’re just going to do it for me, which is very natural because they do produce. Yeah. And that’s, I think, is just an extremely enticing output. I just think it’s like, I think it’s like risky for society. I mean, I think we’ve seen how like people who grew up on social media have like a lot of issues with attention. I think people who, I don’t mean attention trying to get attention. I mean, attention, like staying focused on a task. I think in the same way, people who overgrow up in their work life on LLMs risk under-investing in depth. And I think that’s particularly dangerous in a world where with LLMs, Actually, it may not appear this way in the moment, but like depth is the most important thing.
Swyx [00:59:05]: I would push back a little bit in terms of, I think I’m maybe a bit more slob friendly than you guys. Are you? Just because like slob comes from humans and slob comes from AI. What just matters is like when you sign off, when I send you the document or when I send the PR, I am signing off on the whole thing. I can’t abdicate responsibility to the LLM. Maybe LLM had good output, maybe not, but I’m the final judge, I’m the editor, right?
Emily [00:59:28]: So I actually think we’re on the same page there. So I am like all for using it in the generative process. Actually, it was really cool. It’s a tool for thought. It’s a tool for thought. And it’s a tool for rapid experimentation and rapid iteration. And I love to look at like a demo or a prototype that like I don’t want to see a doc on it. I want to see like the quick thing that you spun in whatever tool you use. Actually, when we were working on claimable sandboxes, I’ll never forget Vercel. Vercel sent us basically like the V0 of like how they thought it should be implemented, just like the UI. Like this is what we think the experience should look like. And it was extremely clarifying, like much more clarifying than hours of meetings and pages of design docs. And so all day long on the generative, but like you need to like deeply put your stamp of approval before you push the PR, before you publish.
Swyx [01:00:19]: I did want to double click a little bit on both, you know, like two primary use cases on RAG and writing code. Just one. Just I guess on like in internal information, there is obviously Glean, which we talked about yesterday, and just all the other internal code search tools. You guys use Notion as well. Is RAG still relevant? Is that something that’s like in active development or what’s beyond that? What’s like the frontier?
Toolshed and Internal Tooling for RAG and LLM Integration
Emily [01:00:43]: So we’ve actually been leaning in really hard on, we call it tool shed, but it’s like a, it’s like an internal like MCP server that basically has access to like all the Stripe tools. Yeah. And, you know, what I like about that. And it’s managed centrally, like, you know, there’s, you know, it’s managed centrally and it plugs into, we’ve since killed that GoLLM thing I talked about. And we did a new like a, you know, implementation, like open source, like Libra chat situation, which is great. But it like hooks up to all those same tool shed, like, you know, MCP servers. And it’s got, you know, I mean, everything you would think like Slack and Google Drive and Git, but also like access to Hubble. So it can see like our data catalog and all the data and it can query the data and, and, and. And I think that’s. I think that’s been really powerful. I don’t think RAG is dead. I do think there’s an important name of the game around, it’s not just like the information that’s available in all those tools. It’s also being able to interact with all those tools, right? It’s like the tool calling. And so I think they coexist and I think they, I think they coexist together. Also, while tool shed is owned centrally, anybody can, so you can, you know, the, the Salesforce team can add Salesforce and, and, and. Because we don’t want to be blocked on some central team in order to have those tools exposed to, to the LLMs and to the agents for Stripes. Yeah.
Swyx [01:02:04]: You want to decentralize a bit. And then code wise, you know, coming on the code side, obviously closer to home for me, I think it’s also like an economist problem of measuring productivity. It is.
Challenges in Measuring AI Coding Productivity and ROI
Emily [01:02:15]: Okay. Well, now you’re just making me feel guilty for not having cracked it.
Swyx [01:02:18]: No, no. I mean, it’s, it’s unsolved globally. I’m kidding. It’s hard. It’s hard.
Emily [01:02:22]: Yeah.
Swyx [01:02:22]: And that’s the thing. Like you, you, you’re looking at the cost and you’re like, oh, it’s pretty high. I don’t know. Maybe we like move to open source models or something, but like, you don’t know the productivity gains you’re off. You’re, you’re getting an interim and you have pretty expensive engineers. Like it’s, it’s hard to tell.
Emily [01:02:36]: Engineers are expensive engineers also like all of us, right. Are hyper-motivated to do the best work of their lives. And so there’s an important component of like, if the people want it, like there’s inherent value in, in providing it, right? Like when people have the tools that they want, are learning the things that they want. Like they work harder, they’re more creative, they produce better output. So anyway, there’s all this like sort of soft fringy stuff that I think is added value above and beyond the actual, you know, production output. And then there’s also like the learning curve, right? So, I mean, we think about this a lot, like when you launch a new traditional ML model or now like AI solution, right? Like if you over-focus on the results in the immediate short-term window, you really risk getting a false negative. Like it’s not good enough. It’s not tuned yet. It doesn’t have the feedback loop yet, you know, hasn’t had time to get the training data to get better. And I think that’s like kind of particularly true in, you know, AI, because you, when you’re working with LLMs, it’s like, well, with like GPT-4, like it didn’t work. And then you’ve swapped in GPT-5 and all of a sudden it does, or we use like a GPT-4-0 and it was like kind of a little bit expensive to justify the humans that it was replacing for a particular risk-related task. But then next thing we know, like O3 Mini is out and it’s like, you know, $3 million a year savings for the business, both because the model is less expensive, but also more importantly, because it replaces more of the humans. And so I do think that like when I think about the optimal adoption of these AI tools, it seems wrong to focus on in-year ROI. And it seems right to focus on two-year, three-year ROI. Now, enhance. It’s inherently hard to know what two or three years is going to look like. But if we look at the history, models getting much better, much more quickly, models getting quite a bit cheaper, quite quickly. It overall makes me bullish that we shouldn’t over-obsess around in-year returns. Yeah.
Swyx [01:04:45]: In-year returns. That’s a good term I never thought about.
Emily [01:04:48]: Especially when the economy is doing so well.
Swyx [01:04:49]: Advertising it like that. Yeah.
Alessio [01:04:51]: What about data? What about data? I was going to move to the data side. Wait, what about data? Yeah. You know, it’s like, oh, are the engineers more productive or not? Like, what about, yeah, like, I mean, text is equal, right? It’s kind of like the first iteration of this. Like, what’s the productivity like on like, I mean, you can generate any chart now, right? But like, does it mean it’s good?
Text-to-SQL Assistants and Data Discovery Challenges
Emily [01:05:11]: Yeah, yeah. So we have this, he’s not really a guy. He’s an AI, but his name’s Hubert, which sounds like a guy. So we have this guy called Hubert, which basically is like natural language to ask questions about the business. By the way, we have a Sigma assistant. So like, our users can query stuff about their business on top of Stripe data. That’s a much more constrained problem because your Stripe data is like your revenue data. It’s like very well structured. It’s very well documented. It’s available in the dashboard and in Sigma and in Stripe data pipeline. You can hook it up to whatever. And so, you know, a text to SQL experience sitting on top of that, like, it’s not going to be perfect, but like, it’s pretty airtight. And by the way, like, if you use natural language to describe what you want, we write the query. And then we also tell you in natural language what the query is. So even if you’re non-technical, you can validate it. Okay. Now imagine there’s a lot of tables at Stripe. There’s a lot of nuance in Stripe data. There’s a lot of nuance in Stripe’s business model. Hubert is the guy that sits on top of this Hubble tool, which you use to find, explore, and query Stripe data that does that internally. And it’s early. I mean, we have like 900 people who use it a week. We have tried to focus the people who use it mostly on... Technical folks who know the domain for exactly the reason you were citing earlier, which is it could get the answer fundamentally wrong. And technical folks are going to be better positioned to validate and provide feedback. One of the most interesting things to me as I was going through the Hubert evals was the place where Hubert did the worst was around data discovery. That is to say, it had a hard time finding which table and which field was best to answer the question at hand. And, I mean, personally... As a user, when I know the table, I actually now just articulate the table in the chat interface. But more importantly, we’re doing a big push right now to deprecate low-quality tables and have the owners document high-quality tables. I haven’t yet figured out if I trust an LLM to do the documentation. So, for like the canonical data sets, we’re kind of brute-forcing it with humans who know the domain. The other thing that we are exploring, but we haven’t landed yet, is offline, it looks like there’s actually really... Like, Hubert.com. It does much better if you tell it where in the organization I sit, because it knows, oh, I’m interested in LPM data, or I’m interested in link data, or I’m interested in OCS data. People who work on the optimized checkout suite tend to query these tables, look at these fields, ask these kinds of questions, look at these types of metrics. Now, that’s not in production, but I think there’s this interesting question of, like, we can have humans do some, like, prompt engineering or documentation or whatever. But we can also give the LLM more just historic... We can also give the LLM more just historic context about what people like me liked to do, basically. So, that’s the next step there. I’m bullish on it. I think... I don’t know if it’s going to be two months or two quarters before, like, everyone’s on it. Like, I think it might take some time to get high enough conviction that we’re not going to have an important wrong answer. Text-to-SQL is really easy, though, with really well-structured, well-documented data. It’s just most data is not well-documented and well-structured.
Improving Data Infrastructure and Real-Time Access
Swyx [01:08:18]: Well, so, before... Immediately before this, I was actually in the data engineering industry. We talked about... And you said you didn’t have an opinion. But I always thought that, like, data discovery is the important victory or, like, the ultimate victory of data catalog people and semantic layer people. Do you agree with those movements in the data world? Do you have any tweaks on the modern data stack that you have?
Emily [01:08:42]: So, we are increasingly moving to, like, semantic events infrastructure. I think the value of near real-time, high-quality... Well-documented data is about to skyrocket because I’m pretty sure that nine months from now, no one is going to want to go and, like, look at a even, like, static dashboard and click around. They’re going to want to be fed insights or they’re going to want their agents to be fed insights and they’re going to want to be able to just, like, pull real-time, high-quality data. For us, what that looks like, like, the two most important domains for our users... In that regard are payments and this, like, usage-based billing, which needs to be very, very real-time for all sort of, like, the AI business model stuff we talked about. And so, there, our path is, like, semantic events, canonical data sets available in near real-time in dashboard, yes, because some people will still use dashboard, in Sigma, so, like, queryable, but also in sort of a Stripe data pipeline type, right? Because very few people want to look at Stripe. They want to look at Stripe data in isolation. They want to look at Stripe data connected to the other stuff, right? So, I mean, you could just even imagine, like, pulling into BigQuery or whatever. They want to see it connected to other stuff. And, you know, historically, honestly, like, it wasn’t all the same data feed for all of those products, and that also creates confusion. So, we’re doing a bit of a re-architecture for that flow starting in the next six months with just billing and payments, and then I think we’ll expand from there. There’s always going to be... There’s always going to be a bunch of data that, for whatever reason, doesn’t fit your, I like to call it a North Star architecture, but, like, your North Star data architecture, right? And I wish that someone could figure out how to make sense of the old bad data so you don’t have to, like, re-architect everything and throw away the old, right? Like, you’ll always have, like, okay, you know, like, there’s, like, the Stripe.com website, which happens, like, you know, before you even create an account. It’s a very different type of data. But, like, you know, how should I reason about that? How should I manage that? And I think traditional enterprises deal with this a lot.
Build vs Buy Decision-Making at Stripe
Swyx [01:11:01]: Like converting website analytics to signed-up users and all that? Yeah. Oh, I’ve thought about that so much. Oh, yeah? You just need, like, it’s kind of fingerprinting, which is, like, something that people are kind of uncomfortable with, but you can. You can do it.
Emily [01:11:15]: Yeah, yeah, yeah.
Swyx [01:11:15]: We have, like, a couple questions on, like, I think there’s a build versus buy question. Yep. On you’re building a lot of internal tooling, and that’s great. But also, there’s a lot of great tooling out there. How do you navigate this? Obviously, you have a lot of unique internal context, but you also have, you work with external vendors. Like, people, I guess, want to know how to work with you, but also people in your shoes at peer companies also want to know how you do this decision. Yeah.
Build vs. buy decisions for internal tooling
Emily [01:11:40]: I think for us, it’s not an either or. It’s very much an and when it comes to build versus buy. And some of that and is sequential, right? So, you and I were talking earlier. When GPT 3.5, I think, like, first hit the scene, we’re like, oh, everybody at Stripe needs to have access to LLMs, but, like, we don’t quite know how to do that in a way that’s, like, enterprise-grade safe and we feel good about. Like, we don’t see a provider there right now, and so we built it. But now we use, like, open source, LibraChat, you know. So, I think there’s, like, there’s, like, an evolution over time. And one of the things that I think can be really hard, especially for the team who has tunnel vision for the products they own, you know, you love your product, you want to make it better over time. Yeah. Because you can get stuck in a lot of hill climbing. Like, we could have taken Go LLM and been like, oh, we should figure out a way to, like, give it access to Toolshed. Oh, we should figure out a way to make it do, like, deep research or, you know, like, we could have done that. And sometimes you just need, like, sort of more of an outside-in perspective of, hey, if I ignore the sunk cost fallacy, ignore my emotional connection to the thing that I spent nights and weekends building, first principles, like, if I were to do this today, what would I do? And some of that is also making sure people. A lot of confidence and conviction in their own abilities and the fact that there’s a ton that they can contribute to the company across domains to kind of liberate them from needing to own this product. Another thing that we’ve done, and this is especially true in the AI space just because there’s, like, so much new stuff coming online. We call it the spotlight program. But basically, like, we put out RFPs for products that we want to buy. Ooh. So one example that we did recently. I guess it was, like, a year ago now was evals. So we were, like, okay, here’s our problem with evals. Like, who’s going to solve it? And we put out this RFP and the spotlight program. We obviously see a lot of these companies directly because they run on Stripe and or, like, their investors have some affiliation with Stripe. And so we know them. So we actually had, like, more than two dozen applicants for this evals RFP. There’s no way you can evaluate all of them. Well, we actually, we did. Oh, my God. They wrote, like, nice one-pagers. We read them all. We narrowed it down to two finalists. Braintrust. Braintrust ended up winning. We did a POC with them. We’ve had them on, yeah. They rock. We stuck with them. We also love, like, Weights and Biases, Flight, Kubernetes. Like, sort of, like, sort of, like, the basic stack you can think of. But there have also been cases where we have had to build. So one example is, if you think about traditional ML for a second, also relevant in the world of, like, our foundation models and that embeddings basically, like, can become features, our feature engineering platform. So we had a homegrown feature engineering platform. It was old. It was on its last legs. We had a team internally that really wanted to adopt Tekton. We evaluated Tekton. This was a couple years ago now. At the time, we couldn’t wrap our heads around using it on the charge path, just from, like, a latency and reliability perspective. Like, we’ve got to be operating at six nines. We’ve got to be, like, decisioning in, you know, tens of milliseconds for some of these models. Like, we just, we can’t reason about that. We can’t reason about that on the charge path. We ended up pairing up with Airbnb and building, we call it Shepard internally, but it’s open source under the name Cronon. You know, I think there are cases for both. But we always start with, like, what could we buy? Sometimes those are obvious solutions. Then we say, oh, there’s no obvious buy solution, but, like, maybe there’s some new startup thing. Let’s run the Spotlight program. And if we really come up dry, then we will build. And as we build, we reason about, okay, six months from now. Twelve months from now, should we still be building or should we actually swap in a buy solution because the market has evolved? The other thing that we feel pretty strongly about in the world of AI is there will be many model providers. There will be many models. And we do not want to hitch our wagons to just one horse. You know, there’s lots of enterprise-grade versions of choose your LLM provider. Like, that’s of much less interest to us. Um, then solutions that sit on top of many different providers and many different models and allow us to swap in and out. Yeah.
Stripe’s Experimental Projects Team and Embedded Innovation
Alessio [01:15:57]: And this is the Stripe experiments team. When you decide something, we need to go. You have the same people always do this.
Emily [01:16:04]: Or do you rebuild this team based on if it’s evals or if it’s like, it’s probably a bottoms up, like whoever it’s bottoms up. So experimentation happens in a lot of different places. So like for the evals, we just did it. Like we ran it within ML infra with like the new rebuild of GoChat. We paired up. We paired up someone from EP with the people who had been owning, um, go LLM, you know, one of the things that’s interesting about experimental projects is the goal is to learn quickly, whether there’s product market fit, whether that’s with your internal users or your external users. But the goal is to basically get to escape velocity, like have a product that launches and goes live, whether that’s like GoChat GA and replacing go LLM or whether that’s like token billing, uh, serving our users or agentic commerce now being a thing. And what we found. And, you know, this is the experimental projects team has been around, um, about a year and a half. And so these are relatively small samples we’re talking about, but what we have found in that sort of Anik data is what we call embedded projects, projects where you take a couple people from a product or infrastructure team and a couple people from the experimental projects and group them together are more likely to reach escape velocity. Token billing is a good example, right? Like we need the billing team to take it forward. And if the billing team was like core to it from the start, it’s much easier for them to take it forward. Same thing, you know, if, if the ML infra team, you know, deeply understands the new build and feels ownership over it, it’ll be successful, um, in the long run. So I don’t think of that, you know, some people think of these teams as like labs teams off in the side, off in a corner operating totally in isolation. We do some of those, like we’re doing that for agent pay, like agent to agent payments. Cause that, that just like needs a big, rev on like what’s the product shape, what’s the technology shape, but wherever possible, we actually do it as a joint project, very deeply embedded with design partners, like with customers that want to do it with us, but also with, uh, with other teams that stripe.
Swyx [01:18:01]: My typical line on just, just closing the loop on the build versus buy thing, uh, is usually buy then build. If you think about the sequencing, I think yours is, yours is much more nuanced in terms of like.
Emily [01:18:12]: Buy then build if a buy exists. Correct. If a buy doesn’t exist, you might want to build, but pick up your head of recording. To make sure you can’t buy. Yeah. Yeah.
Swyx [01:18:20]: Well, and also I think like mostly because I, I see the opposite when P a lot of people try to do the opposite of build then buy to, to, to like reason things from first principles, but actually, uh, the sheer amount of experimentation in the wider world means that a lot of people are being specialists in your thing, like devils, where you can just benefit from that, from their experience instead of, uh, reinventing the wheel.
Emily [01:18:43]: So before Stripe, I was at Coursera. Have you guys ever looked like the ed tech platform? Okay. Of course. I was there for eight years and I joined when we were less than 40 people and it was a lot of absolutely brilliant folks from Andrew and Daphne’s lab at Stanford who had never had a job before. And by the way, I do not count myself in the absolutely brilliant folks from Andrew and Daphne’s lab. I was on the east coast, um, and not absolutely brilliant, but I had also never had a job before. And a bunch of us never had a job before, but like really hardworking, determined people built a bunch of stuff homegrown that we shouldn’t have. Right. Yeah. We had our own experiment. We had our own experimentation platform. We had our own analytics platform. We had our own machine learning platform. We had our, uh, we learned a lot. We learned a lot. But like, what is Coursera’s core competitive advantage? It’s not their experimentation platform. Um, and you know, that was 2014. So actually a bunch of that stuff didn’t exist, but it was painful in 2018, 2019, 2020 to rip and replace and rip and replace was definitely the right thing to do. The other sort of, um, thing I’ll note on that is if you look at how Stripe is the skeletal system. I mean, if you look at the AI system for all the AI companies, it very quickly becomes clear that when it comes to payments, billing, tax revenue recognition, reporting fraud protection, consumer checkout experience, pricing and monetization frameworks, they are completely by like, they’re completely buying Stripe. That’s all they’re buying. Um, and I think there’s an interesting thing there where I was talking to an AI company the other day who uses another provider. Yeah. block bots at the time of signup. And they said, it’s actually really annoying to have multiple third parties doing my fraud protection, like one doing it up funnel and the other doing it down funnel. Well, they asked to switch to Stripe. We don’t yet have that particular functionality, but we could build it. But I think there’s also, it’s also important to reason about what is the third party that you can be, not for everything, but like more all in on so that it plays nice internally so that you have fewer relationships so that you have like preferential pricing, et cetera, et cetera. And you know, when you think about cloud providers, like that often
Swyx [01:20:50]: happens a lot as well. Vercel is definitely doing that. Totally. Trying to bundle. Yeah. So this is the economy section. We were saying you’re more interested in sort of the AI economy
AI Economy Analysis and Business Model Trends
Emily [01:20:59]: takes. The obvious big one is, are we in a bubble? Are we in a bubble? Okay. So it depends what you
Swyx [01:21:04]: mean by a bubble, but I think, you know, one question. Classic economist answer is like,
Economic analysis of AI companies and market dynamics
Emily [01:21:10]: it depends. It depends. I know, There’s always, there’s like two armed economists on the one hand, on the other hand. Okay. Okay. Okay. Okay. The question I got a lot a couple of quarters ago, especially because all of these AI companies are private, is are they creating real value? Is there real revenue coming in? Right? Because it’s pretty clear to see that there are real costs. There’s very big fundraisers. There’s a lot of capital that’s flowing out. Is there dollars flowing in? And so that actually forced us to
Swyx [01:21:41]: step back. You know, one of the fun things at Stripe is just like, you just see it going through,
Emily [01:21:45]: right? You see each successive wave of startups. You see, you know, people retaining and churning their subscriptions. You see who’s buying what for how much from whom. And when we stepped back and we said, okay, like, let’s just look at this AI cohort. And there’s lots of different ways to define it. But for simplicity, one cohort that we looked at was the 100 highest grossing AI companies on Stripe. And you kind of need a reference point. And so we were like, let’s compare them to the 100 highest grossing SaaS companies from five years. And we looked at things like, how quickly do they get to a million or 10 million or 30 million in ARR? And the answer is two to three times as fast as a SaaS cohort. Yeah. We looked at questions like, how diversified, global is their customer base? And the answer is, at the end of their first year, at the end of their second year, basically, whenever you look, they are twice as global. Like, they’re selling into twice as many countries. 55 countries. They have more. Majority of their revenue coming from outside their home market, even if their home market is the U.S. And in some cases, you know, there’s a startup in France who’s in that list, who’s like 95% of their revenue is outside of France, right? They’re very global. And then you start to look at things like retention, which also comes up a bunch, right? Like, is this truly ARR or is this
Swyx [01:23:07]: like revenue popping and then falls off? Times 12.
Emily [01:23:11]: Exactly. And this one was a little more nuanced. So, if you squint at the data, you can actually see that these AI companies on a per-company basis have slightly lower retention than the SaaS companies. Not, like, dramatically lower, but slightly lower. And that’s also consistent with being, like, relatively early in the adoption curve, but even correcting for that, slightly lower. But then if you bundle that, if you look at, okay, like, these SaaS companies are doing this wave of things. These AI companies are doing this wave of things. What’s interesting about SaaS is the churn is churn from the entire vertical. In AI, They’re just churning from that company and flipping to another company. And then if you keep watching them, a few months later, they flip back to the first company. So that tells me it’s actually like a very competitive market. People like the product. They want to use the product. But there’s a bunch of good products. And the best product is changing over time. And so people are happily flipping across. Oh, well, so in SaaS, you had this cool trend of you started horizontal. You started with Salesforce. And then you went vertical, like you have the vertical SaaS, the toasts and the whatever else. We talked a bit about wrappers earlier. AI has done the same thing. You start horizontal, right? You’re like the infrastructure. You’re the model providers. You’re the purely horizontal. And then all of a sudden, it’s like all of these verticals. It’s like, OK, we’re in healthcare. And there’s Nabla. And there’s Ascribe. Or we’re in architecture. And there’s Studio. Or we’re in law. And there’s Harvey. Just like all of these verticals popping up. And popping up much faster than in SaaS. And I think there’s two things happening there. One is you can get to those verticals very efficiently because you’re sitting on top of someone else’s LLMs. You don’t actually have to do that. You don’t have to do the research. And it’s like a quite lightweight build. But the other thing is, because these AI solutions are so borderless, niche markets, vertical markets, at a global scale, are actually quite large markets. And so there are incentives to specialization in a way that maybe there weren’t five years ago. So anyway, is it a bubble? I don’t know. It depends how you define a bubble. I’m a two-armed economist. But what I will tell you is. Because these are companies that are growing very quickly, faster than anything we’ve ever seen, very diversified in their customer base, which makes me feel better about them. Very sticky in their customer base, not always on a per company level, but on like a problem to be solved level, which tells me that the customers are getting recurring value from the product and are willing to pay for it. Yeah.
Revenue, Churn, and Retention in AI vs SaaS Startups
Swyx [01:25:34]: What I’m hearing is like, there is some real, like better quality businesses being built at the same time that it has no, the expectations can raise. And that’s not within the Stripe observable universe. Yeah.
Emily [01:25:47]: The part we didn’t, I mean, the part we didn’t talk about was the cost profiles and, you know, when I reason about cost profiles, there’s really like two, there’s like the fixed costs and the marginal costs, or there’s like the people costs and like the, I mean, in the case of AI, like the inference costs. Right. And so the people costs for these AI companies are quite small, right? You look at a lovable, you’re talking crazy revenue milestones. Right. With 10, 20, 30, 40 people in the early days. And even today, right, when you, when you look at most of the top 100 AI companies on Stripe, their revenue per employee is unlike any other business, including public companies who are known for being incredibly efficient companies. That of course, people cost ignores the inference costs. And so I think we absolutely need to model assumptions around the efficiency and where the inference costs is going in order to be able to. But in the same way we were talking about, how do we think about the ROI on, on these coding agents? I think we would be unwise to measure the value of these companies under the assumption of today’s costs. And we need to model out based on, you know, reasonable things that we’ve seen and reasonable expectations we have about the world, like those costs going down quite a bit, at which point, you know, in traditional senses, like very interesting businesses. Yeah.
Cost Profiles and Unit Economics in AI Startups
Swyx [01:27:08]: I would say like, you know, there’s the benign element and then there’s the less benign in terms of the cost profile, which is yes, as, as AI is increasingly doing more and more labor that you, you would otherwise have hired for, then it should rise as, as a part of your spend. And then there’s the less benign one, which is like people are selling dollars for 50 cents. And that’s why you’re, you’re seeing such revenue traction because obviously you’re kind of giving money away.
Emily [01:27:32]: For sure. And, you know, like I, I was a grad student in the early days of Uber and DoorDash or, you know, I was year one. And two of Coursera, which was like, that’s still a.org at that time, right? Like basically a nonprofit. And I remember my lifestyle was subsidized by the VCs who were paying for part of my Uber and paying for part of my DoorDash. So, you know, we’ve lived that pain. Those two worked out. Some of those prices going up. But increasingly what we’re seeing from the AI companies on Stripe is they do want to have healthy unit economics. I mean, let’s not talk about like the big labs that are pouring crazy money into research. But if you’re talking about like the vertical kind of wrappers, which are themselves also doing, you know, like, you know, like, you know, like, you know, like, you know, like, you know, like, you know, like, you know, like, you know, like, you know, like, you know, like, very well as businesses, they are building quite healthy unit economics. And the demand we’ve seen for token billing, I think, is actually in part a testament to the fact that they really do want to have unit economics. So not their overall book, but literally like the marginal person I serve, the revenue I get from them versus the cost I incur for them, they want those to already be in the green. So I think there are some some very good businesses that are being built.
Swyx [01:28:37]: We’ve kept you for a long time. You’ve indulged us in so many different topics. Do you have any other hot takes on AI in the economy that you want to indulge in? My classic hot take is how come AI doesn’t show up in the GDP per capita numbers, which is part of the whole productivity discussion, but it’s really, really driving home. We have to see this show up somehow, and that’s part of the bubble discussion. But I think to me, any story where technology as a factor in the macroeconomy equation is supposed to be a big driver, you should see it in GDP at some point. GDP doesn’t measure everything, but at some point.
Impact of AI on GDP and Global Economic Growth
Emily [01:29:16]: We should see it in GDP. There’s a lot of noise in GDP because there’s a lot of other drivers of GDP.
Swyx [01:29:21]: How quickly we see it is, I think, an open question. It should be fast. It should be fast-ish. The funny hot take is the only way we’re seeing GDP is the data center build-out. Oh, interesting.
Emily [01:29:34]: Oh, yeah. I’m less close to that. It could be. I mean, hot takes. I think AI should make markets more efficient. I think agents should make commerce more efficient, which should genuinely expand the aperture of what people buy. I think agents are already making business creation more efficient, which should accelerate new startup growth, which we are also seeing. And, you know, if you just think about, like, the tens of thousands, hundreds of thousands of businesses that are getting started in these AI dev tools that, like, would not have been getting started before, I think that’s incredibly promising. I think we have a real cost question on our hands, but I think it will be solved. For many domains, I think there will be cheap enough models to do the job that create meaningful value. I think the AI... Like, companies are being quite savvy. We talked a bit about the unit economics, but also, like, what are they pricing to, right? So, SaaS was mostly seat-based, and you could imagine sort of a death spiral where, like, AI is seat-based, but AI is replacing the seats, and so you need fewer seats, and you monetize less. Like, you don’t want to peg your revenue to the thing you’re trying to replace, right? And I think, you know, outcome-based or usage-based will be... Much more powerful. I’m seeing more adoption of AI outside of the U.S. in a broad range of markets than I expected.
Swyx [01:31:11]: Brazil is huge. Brazil is huge. Yeah.
Emily [01:31:13]: It’s a little bit hard to parse what is, like, well, Stripe is opening up more markets and having more payment methods and giving them more exposure versus, like, literally there is an expansion in adoption. But I think it will be promising for the world if there is more... It’s not really a quality of access. It’s not really a quality of access because, like, on paper, anyone has access, but, like, equality of adoption so that we don’t lead to sort of... We don’t end up with very uneven economic growth as a result of AI. So, we’ll have to watch. I don’t think it’s going to show up next year. I don’t think most businesses are targeting employee efficiencies next year, but I think every business is targeting employee efficiencies for 27 and for 28. Yeah. Which is suggesting more efficiency. And if you can couple more efficient production with more efficient consumption, which, frankly, is what agents do, then one would expect, yes, GDP to rise, to rise meaningfully. And I think you could debate, is it one percentage point more growth per year? Is it three percentage points more growth per year? Like, I don’t know. I don’t think it’s 10. I don’t... I mean, I’d love it, but I don’t think so. I think we’ll have to see. Because that thing compounds, right? That thing compounds. That thing compounds.
Swyx [01:32:32]: GDP is a big number. Yeah. But yeah, the term I’ve had for the movement of employee efficiency is tiny teams. Like, you know, teams with more millions in revenue than employees, which, like, completely changes the startup structure because you are probably profitable from, like, maybe your first round of funding. Yeah.
Tiny Teams and Importance of Brand in AI Startups
Emily [01:32:51]: I have one more hot take, which is it’s easy to think in a world of, like, really exciting, powerful tech that somehow brand doesn’t matter. It’s all about the technology. But actually, if you look over the last year, so much of the, you know, value created in AI companies has actually come from... And Lovable was brilliant in branding themselves Lovable, right? Like, so many of these rappers are actually winning on a really differentiated user experience and a really compelling brand and a really compelling community. And so, I don’t know. I just... You know, sometimes, you know, investors, friends, whatever, will be like, like, oh, like, what do you think of this? What do you think of that? And it’s like, you know, great founders who are highly technical are amazing, but you also need them to be hyper-focused on, like, the user and the product experience and really creating something, like, beautiful and craftsy. And I think some people are like, oh, like, AI should replace that. And, like, all that matters is the tech. And there’s not going to be a human internet. And it’s just going to be agents talking to agents. And it’s like, I don’t know, maybe, but, like, so far, what I’m seeing is brand matters more than ever. Yeah.
Swyx [01:33:57]: The Silicon Valley phrase is you need Riz and Tiz. And if you don’t have Riz, then it’s awful. I think, like, Stripe, something Stripe has always embodied, like, very good technologies with also industry-leading design, which I think is very important.
Emily [01:34:11]: I’m a Katie Dill fangirl. Katie Dill’s our head of design. Oh, okay. Actually, I was co-hosting Friday Fireside, which is, like, our weekly company thing today. And I cited something that Katie’s team did and made it clear that I was a fangirl. And Tanya, who’s our head of PMM, said she was going to have to fight me for, like, Katie’s biggest fan. Anyway, we decided that the three of us would just go to a spa and drink mimosas instead of fighting. But for a hot second in the company’s Slack chat, there was, like, maybe a fight between TK and I.
Design Quality Culture at Stripe
Swyx [01:34:42]: Okay, let me, while you’re on this topic, what’s something that you learned from her that, like, has really driven design at Stripe? Yeah.
Emily [01:34:49]: Katie does not give an inch on quality. And it doesn’t matter if it’s, like, one banner that 2,000 users see. That, you know, has some font that’s slightly bigger than it should be. Like, that’s a bug. That has an SLA. That needs to be burned down. And actually, now every two weeks we have a run the business review where it’s, like, a 60 folks get together and talk about the whole business. And literally each of us has a slide that’s, like, did we meet our bug burned down SLA for these, like, largely, not exclusively quality, but often quality issues. And I think she builds, like, beautiful experience. She and her team design, like, beautiful experiences and sort of, like, macro are, like, extremely innovative. But there’s something that I’ve learned around, like, the micro. Like, you have to obsess over every detail. And one tiny thing that’s not good enough is worth all of us sweating until it is good enough. It can be a little exhausting at the scale of Stripe, but it’s also, like, very grounding. Yeah. To just know, like, there’s a clear line. And if it doesn’t meet the quality bar, like, you just got to fix it.
Swyx [01:36:07]: Wow. Well, thank you for spending some time with us and explaining how things work at Stripe. I mean, like, everyone’s always curious and you’ve been very generous with your time.
Hiring Call to Action at Stripe
Emily [01:36:16]: Oh, thanks for having me. And it’s been really fun.
Swyx [01:36:18]: Call to action. Hiring, I assume? Yes.
Hiring at Stripe and closing remarks
Emily [01:36:21]: We are hiring. We are hiring. I mean, we’re hiring everybody. But we are particularly hiring machine learning engineers. Slash scientists. A lot of back-end folks. So, like, if you’re excited to, you know, build the infrastructure for building agents or build the infrastructure to do machine learning, a lot of those. We are recognizing that data is, like, increasingly an asset that our users want real-time and high-quality and well-documented. So, like, if you’re big on data engineering or building data platforms, also hiring there. But just, like, across the stack. It’s, like, a great team and fun project. So, yeah.
Alessio [01:36:59]: We’re hiring. Thanks, Emily. Awesome.
Emily [01:37:01]: Thanks, folks.
143 episodes



